https://arxiv.org/pdf/1905.09788.pdf
NLP 관련 캐글 상위권 솔루션들을 보다보면 간혹 등장하는 multi-sample dropout 구조를 이용해
모델의 일반화 능력을 향상 시키는 것을 볼 수 있다.
관련 논문이 있어 아이디어 정도만 정리해본다.
Dropout의 효과 리마인드
- 예를 들어, 랜덤하게 50%의 뉴런을 매 학습 이터레이션 마다 버림
- 그 결과, 뉴런들이 서로 의존하는 것을 막을 수 있고, better generalization이 가능해짐
- inference 시에는 학습 때 처럼 랜덤하게 버리지 않고, 각 뉴런의 출력에 0.5를 곱함.
Multi-sample Dropout
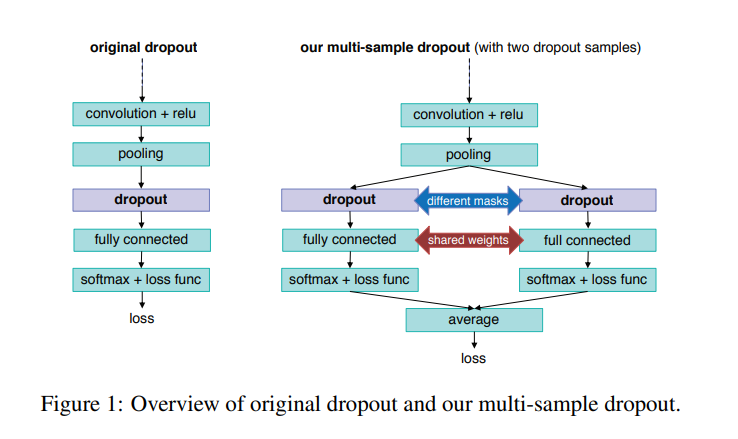
이게 전부다.
BERT를 fine-tuning할 때를 예를 들면,
BERT의 output feature에 대해서 k 개의 dropout을 적용하고,
각 결과에 down stream task 해결을 위한 head를 붙여 최종 출력 값을 뽑고 각각에 대한 로스를 구한 뒤 평균 내는 것.
그림에서는 2개의 dropout samples 을 보여줬지만,
논문에선 64 samples 까지 시도한다.
Multi-sample dropout은 학습 속도를 가속시켜준다는데
(매 이터레이션 학습 속도는 느려지지만, 전체적으로 보면)
그 이유는, 같은 인풋에 대해서 서로 다른 output을 적용하여 k 개의 sample을 뽑기 때문에
mini-batch의 크기를 k개 만큼 뻥튀기 시키는 효과를 가져온다.
다시 말해, 위의 그림 예시 기준으로 <A, B> 라는 인풋에 대해서 <A, A', B, B'> 샘플로 학습하는 효과.
물론, Dropout이 없어서 <A, A, B, B> 를 학습하게 되면,
즉, sample간의 diversity가 없어지게 되면서 multi-sample dropout 을 적용하는 의미가 없어진다.
직관적으로 보면 Self-Ensemble 효과도 있다고한다.
실험결과 적정 dropout sample size는 8, 16 정도가 합리적이라고 나오는데,
뭐 이건 각자 상황에 따라 다를듯!
예시 코드
outputs = self.roberta(
input_ids,
attention_mask=attention_mask,
token_type_ids=token_type_ids,
position_ids=position_ids,
head_mask=head_mask,
inputs_embeds=inputs_embeds,
)
hidden_layers = outputs[2]
cls_outputs = torch.stack(
[self.dropout(layer[:, 0, :]) for layer in hidden_layers], dim=2
)
cls_output = (torch.softmax(self.layer_weights, dim=0) * cls_outputs).sum(-1)
# multisample dropout (wut): https://arxiv.org/abs/1905.09788
logits = torch.mean(
torch.stack(
[self.classifier(self.high_dropout(cls_output)) for _ in range(5)],
dim=0,
),
dim=0,
)github.com/oleg-yaroshevskiy/quest_qa_labeling/blob/master/step5_model3_roberta_code/model.py
oleg-yaroshevskiy/quest_qa_labeling
Google QUEST Q&A Labeling. Improving automated understanding of complex question answer content - oleg-yaroshevskiy/quest_qa_labeling
github.com