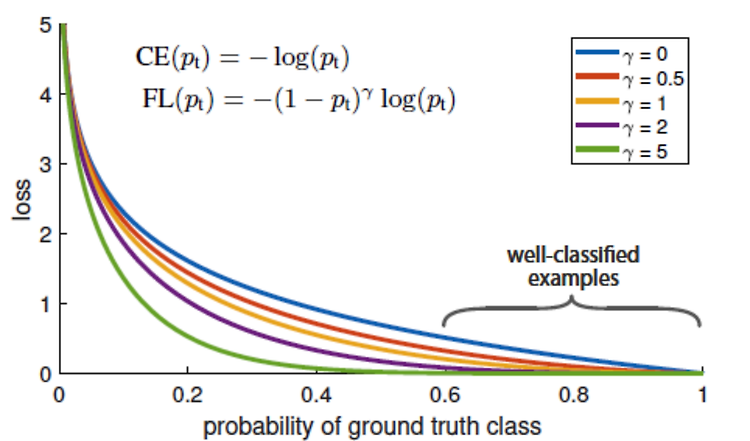
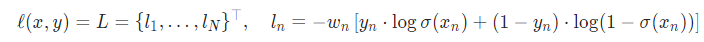얼마 전 종료 되었던 Shoppe - Price Match Guarantee 대회 비록 뒤늦게 참여해서 아쉽게 메달은 획득하지 못했지만, 짧은 기간 동안 즐겁게 팀플레이를 할 수 있었던 대회였다. 상품 이미지와 제목이 주어졌을 때 유사한 제품 id를 찾는 멀티모달리티를 이용한 대회였다. 탑솔루션이 몇 개 공개되어, 상위권 사람들이 보여준 핵심 아이디어 몇 가지를 정리해보았다. 1등 솔루션 (한국인 yoonsoo님, from embeddings to matches) https://www.kaggle.com/c/shopee-product-matching/discussion/238136 eca_nfnet_l1, xlm-roberta-large, xlm-roberta-base, bert-base-indonesi..