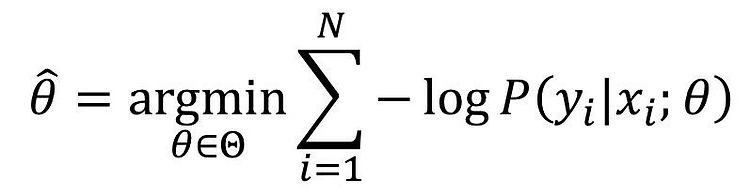Likelihood & Maximum Likelihood Estimation(MLE) Likelihood(우도; 가능도)란? 어떤 모델(파라미터;확률분포)과 데이터가 주어졌을 때, 이 모델이 데이터를 얼마나 잘 설명하는지? 수치화 할 수 있는 척도이다. Likelihood는 모델의 파라미터 θ에 대한 함수이다. 관측된 데이터가 주어졌을 때, 어떤 파라미터 θ가 입력되느냐에 따라 Likelihood 함수 결과값의 높고 낮음이 결정 된다. 예를 들어, 이항 분포의 확률 B(n, p)을 정의하는 확률 질량 함수가 있고 n번 동전을 던져 x번 앞면이 나올 확률은 다음과 같이 구할 수 있다하자. 모델 파라미터 p를 모르는 상태에서 데이터를 관측한 결과 n=100, x=24가 나왔다면 이를 대입한 100C24 * ..