앞서 Seq2Seq의 구조와 학습 방법에 대해서 알아봤었다.
Seq2Seq, Auto Regressive, Attention, Teacher Forcing, Input Feeding
최근에 번역 모델을 직접 구현해보면서 공부하게 된 구조 seq2seq. 개념만 알고 직접 구현해본 적은 없어서 굳이 호기심을 가지고 해본 것인데, 새롭게 배운 것이 꽤 있다. 이해하기 위해선 RNN이나
aimaster.tistory.com
그러면, 추론은 어떻게 할까?
seq2seq을 기준으로
입력 문장(영어)을 컨텍스트 벡터로 인코딩 한 뒤
타겟 문장(한글)으로 디코딩하는 방법에 대해 정리해 본다.
입력/출력 문장을 구성하는 단어 사전의 크기는 3만개라고 가정하자.
디코딩 과정은 곧 매 타임스텝마다 3만 개 단어중 하나를 선택해 나가는 것과 같다.

Decoding 하는 방법 (Inference)
디코더는 Auto-Regressive 방식으로 동작한다.
특정 타임스텝 t에서 생성된 결과를 t+1 에서 입력으로 사용하기 때문이다.
그러면 매 타임스텝 t 마다 적절한 단어(토큰)을 생성할 때,
3만 개의 출력 확률 값 중 가장 높은 것을 선택해 나가면 그만일까? (greedy 한 방법)
그렇게 디코딩을 하면 속도는 빠르지만 문제가 있다.
A B C D 가 정답 문장일 때,
timestep=2 까지
A B 를 디코딩 했다고 가정하자.
timestep=3의 디코딩을 위해
바로 이전의 히든 스테이트와, 이전 출력 B를 고려해 보았더니
아래와 같은 결과를 얻었다.
----------------
0.32 -> G
0.31 -> C
0.05 -> A
...
----------------
여기서, 가장 확률 값이 높은 G만 선택하는게 과연 맞는 방법일까?
A B G 뒤에 올 단어와
A B C 뒤에 올 단어는
완전히 다른 분포를 가질 수도 있는데?
디코더는 Auto-Regressive 하게 동작하기 때문에
특정 타임스텝에서 모델이 헷갈려 잘못 될 여지가 있는 선택을 한다면
뒤에까지 다 틀려버릴 여지가 있다. (물론 비슷한 의미의 단어를 선택할 수도 있다)
이는 곧,
최종 결과의 누적 확률을 생각해 봤을 때 (길이에 대한 패널티 적용을 했다고 가정)
A B G Z W X = 2.4
A B C D = 2.5
와 같이 중간에 1등이 아닌 선택지를 택한 결과가 더 좋을 수도 있다는 말.
* Beam Search
위와 같이 greedy 하게 argmax 확률만 추적해 나가면
모델이 실수할 경우 돌이킬 수 없게 된다.
대안으로, top-k 확률을 추적해 나간다면 어떨까?
아래 그림은 beam_size=2 일 때,
그리고 매 타임스텝 마다 선택지는 5(vocab_size)인 상황을 보여준다.
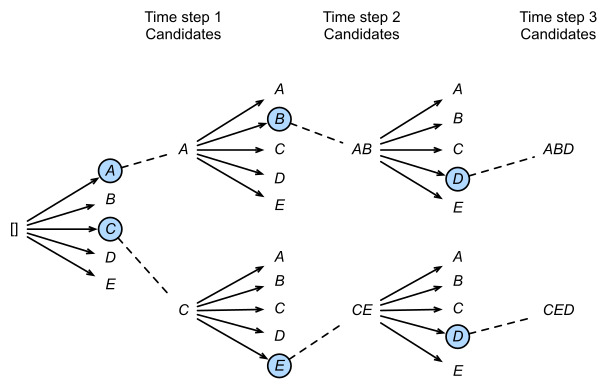
추가로 고려하는 만큼 결과적으론 더 나은 결과를 선택할 가능성이 높아진다!
실제 구현은...
실제 구현은 좀 까다로울 수 있다.
구현하는 방법은 다양하겠지만, 그 중 하나는 보조 클래스(helper class)를 두는 방법이 있다.
빔서치를 위한 보조 클래스는
배치를 구성하는 하나의 example 마다 인스턴스로 생성 되어
- 상태 정보를 기록 (이전까지의 top-k 개 선택, 누적확률, hidden/cell state 등)
- 현재 추적중인 beam_size에 해당하는 상태값을 리턴
- 모델의 출력 결과에 따라 가지고 있는 상태를 업데이트
- top-k의 베스트 결과(문장)를 리턴
와 같은 역할을 수행한다.
batch는 보조 인스턴스를 활용하면
batch * beam_size 로 취급될 수 있다.
모델의 입장에선 배치가 늘어난 것 처럼
평소와 같이 입력에 대해 출력을 뽑아주고,
각 example에 대한 보조 인스턴스에선
해당 출력을 보고 적절히 상태 값을 업데이트 해나간다.
모든 추론이 끝났을 때는,
보조 인스턴스를 통해 가장 높은 누적확률은 갖는 문장을 선택하면 된다!
'DL&ML > concept' 카테고리의 다른 글
| ArcFace Loss (1) | 2021.04.25 |
|---|---|
| ReLU가 Non-linear인 이유? (0) | 2021.04.14 |
| Classification에서 CrossEntropy를 Loss 함수로 쓰는 이유? (0) | 2021.04.13 |
| Posterior, Likelihood, Prior (0) | 2021.04.12 |
| Regression에서 MSE를 Loss 함수로 쓰는 이유? (0) | 2021.04.11 |