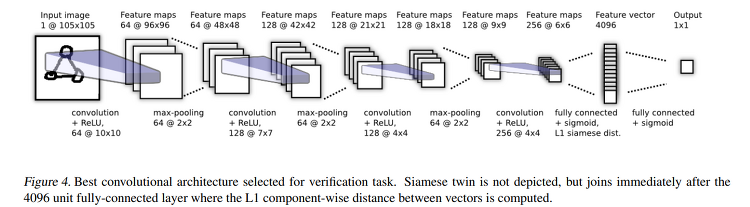
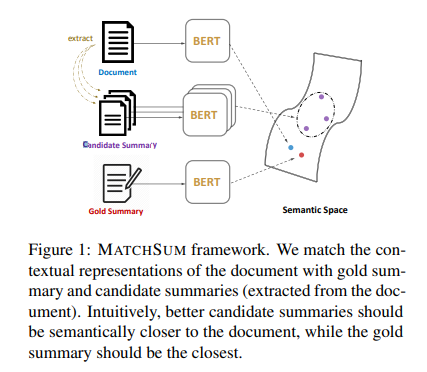
논문 링크 ; arxiv.org/pdf/2002.07033.pdf 지금 참여 중인 Kaggle Competition이다. Riiid! Answer Correctness Prediction Track knowledge states of 1M+ students in the wild www.kaggle.com SANTA 앱에서 축적된 유저의 학습 데이터를 가지고, Knowledge Tracing을 하는 대회이고, 유저의 응답 history가 주어졌을 때 다음으로 주어지는 문제를 맞출 확률이 얼마나 되는지 계산해야 한다. 관련 논문을 훑다가, riiid에서 구현한 모델이 있어서 보니 트랜스포머를 사용하고 있었는데, 주어진 데이터를 트랜스포머에 어떻게 입력을 한 것인지 궁금해서 보게 되었다. Knowledge T..