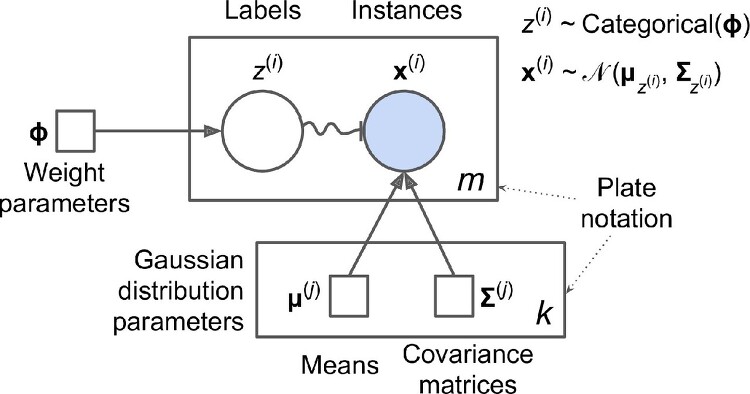
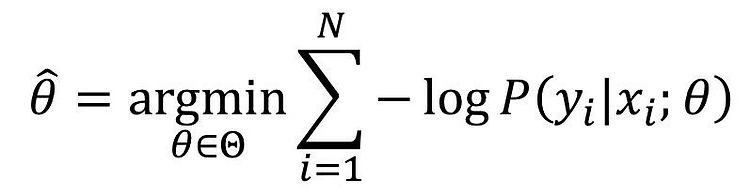Density Estimation / Clustering / Anomaly Detection에 활용될 수 있는 Gaussian Mixture가 무엇인지 대략 살펴 보려 한다. Gaussian Mixture 인스턴스(데이터)들이 파라미터가 알려지지 않은 몇 개의 가우시안 분포의 믹스쳐로 부터 생성이 되었다고 가정하는 확률 모델이다. 가정이 그렇기 때문에, 인스턴스(데이터) x가 주어지면 인스턴스 기반으로 가우시안 분포의 파라미터 등을 거꾸로 추정하고, 새로운 데이터가 확률적으로 어떤 가우시안 분포(클러스터)에 속하는지 여부를 알 수 있게 된다. 하나의 분포(multivariate gaussian distribution)로 부터 생성된 인스턴스들은 하나의 클러스터를 이루며, 모양에 제한은 없으나 보통은 타원..