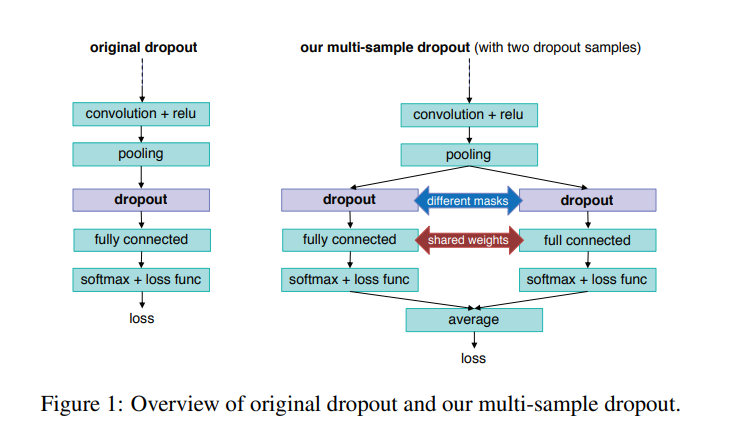
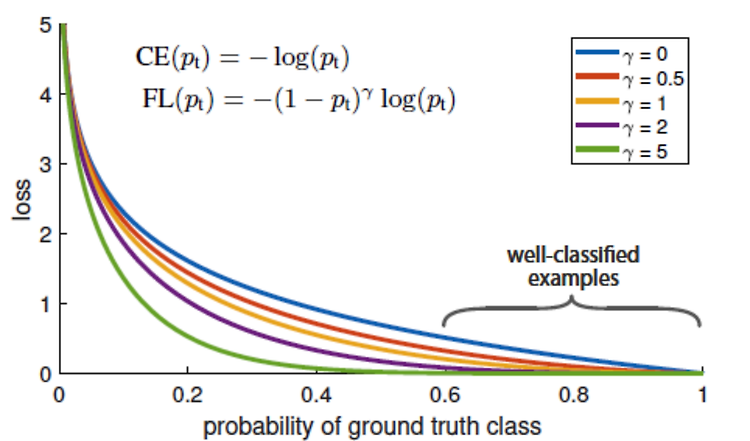
https://arxiv.org/pdf/1905.09788.pdf NLP 관련 캐글 상위권 솔루션들을 보다보면 간혹 등장하는 multi-sample dropout 구조를 이용해 모델의 일반화 능력을 향상 시키는 것을 볼 수 있다. 관련 논문이 있어 아이디어 정도만 정리해본다. Dropout의 효과 리마인드 예를 들어, 랜덤하게 50%의 뉴런을 매 학습 이터레이션 마다 버림 그 결과, 뉴런들이 서로 의존하는 것을 막을 수 있고, better generalization이 가능해짐 inference 시에는 학습 때 처럼 랜덤하게 버리지 않고, 각 뉴런의 출력에 0.5를 곱함. Multi-sample Dropout 이게 전부다. BERT를 fine-tuning할 때를 예를 들면, BERT의 output fe..