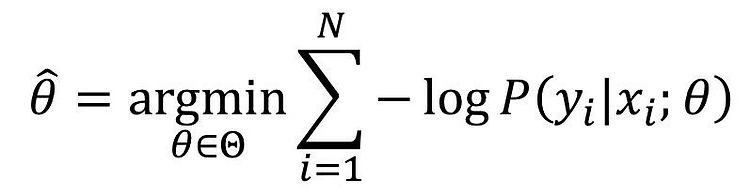Bayes Theorem 조건부 확률 분포를 뒤집어 표현하는 방법 데이터가 주어졌을 때, 어떤 모델을 학습시키는 방법에는 MAP, MLE 두 방법이 있다. 위 수식에서, P(L|features) Posterior P(features|L)이 Likelihood P(L)이 Prior이다. 예를 들어, (김기현님 머신러닝 강의에서 가져온 예시) 절도 사건의 범인이 발자국을 남겼는데 그 사이즈가 240이라면, 범인은 남자인가 여자인가? 의 문제를 품에 있어서 가장 쉽게 접근하는 방법은 Likelihood를 비교해보는 것이다. 여자일 때의 발사이즈가 240인 사람, 남자일 때 발사이즈가 240인 사람을 비교해서 확률이 더 높은 쪽을 선택하는 것이다. 그런데, 이 접근법은 '남녀 성별 비율이 같다'고 가정을 깔고 ..