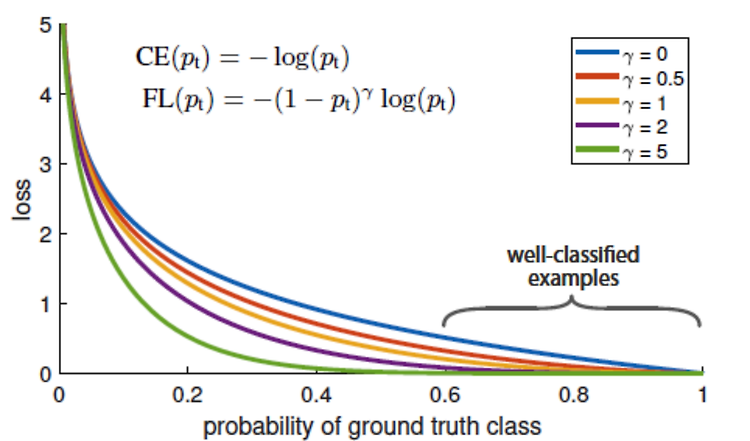
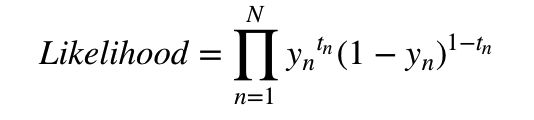Object Detection에서 Background / Foreground Class의 불균형 문제를 로스 함수로 해결하기 위해 제안된 focal loss 이걸 클래스 분균형이 심한 일반 분류 문제에도 적용할 수 있을 것 같아서 살펴보았다.. 핵심 아이디어는 다음과 같다. 모델 입장에서 쉽다고 판단하는 example에 대해서 모델의 출력 확률(confidence) Pt가 높게 나올테니 (1-Pt)^gamma를 CE에 추가해줌으로써 높은 확신에 대해 패널티를 주는 방법 반대로 어려워하고 있는 example에 대해선 Pt가 낮게 나올테니 (1-Pt)^gamma가 상대적으로 높게 나올 것! gamma가 높을 수록 (1-Pt)가 작을 수록 더 작아진다 (확신이 높은 example은 패널티를 더 받음) 일반적인..